Los nuevos modelos de IA como ChatGPT persiguen la ¡®superinteligencia¡¯, pero no logran ser fiables ni en preguntas bobas
Un estudio publicado en la revista ¡®Nature¡¯ alerta de que los errores, incluso en cuestiones sencillas, serš¢n difšªcilmente eliminables del todo en el futuro

ChatGPT y otros modelos de lenguaje se han convertido en un recurso cada vez mš¢s habitual en multitud de trabajos. Sin embargo, tienen un problema de fondo que tiende a empeorar: estos sistemas dan a menudo respuestas incorrectas y la tendencia no es positiva. ¡°Los sistemas nuevos mejoran sus resultados en tareas difšªciles, pero no en fš¢ciles, asšª que estos modelos se vuelven menos fiables¡±, resume Lexin Zhou, coautor de un artšªculo que este mišŠrcoles publica la revista cientšªfica Nature, que ha escrito junto a cuatro espa?oles y un belga del Instituto VRAIN (Instituto Universitario Valenciano de Investigaciš®n en Inteligencia Artificial) de la Universitat Politššcnica de Valššncia y de la Universidad de Cambridge. En 2022 varios de los autores formaron parte de un grupo mayor contratado por OpenAI para poner a prueba lo que seršªa ChatGPT-4.
El artšªculo ha estado un a?o en revisiš®n antes de ser publicado, un periodo comš²n para este tipo de trabajos cientšªficos; pero ya fuera del estudio, los investigadores han probado tambišŠn si los nuevos modelos de ChatGPT o Claude resuelven estos problemas y han comprobado que no: ¡°Hemos encontrado lo mismo¡±, zanja Zhou. ¡°Hay algo incluso peor. ChatGPT-o1 [el programa mš¢s reciente de OpenAI] no evita tareas y si le das un pu?ado de cuestiones muy difšªciles no dice que no sabe, sino que emplea 100 o 200 segundos pensando la soluciš®n, lo que es muy costoso en tšŠrminos computacionales y de tiempo para el usuario¡±, a?ade.
11/ Beyond this paper, we find that difficulty discordance, lack of prudent avoidance and prompt sensitivity still persist in other LLMs released after our experiments, including OpenAI¡¯s o1 models, Antrophic¡¯s Claude-3.5-Sonnet and Meta¡¯s? LLaMA-3.1-405B:https://t.co/2vAKv5gcly
— Lexin Zhou (@lexin_zhou) September 25, 2024
Para un humano no es sencillo detectar cuš¢ndo uno de estos modelos puede estar equivocš¢ndose: ¡°Los modelos pueden resolver tareas complejas, pero al mismo tiempo fallan en tareas simples¡±, dice JosšŠ Hernš¢ndez-Orallo, investigador de la UPV y otro de los autores. ¡°Por ejemplo, pueden resolver varios problemas matemš¢ticos de nivel de doctorado, pero se pueden equivocar en una simple suma¡±, a?ade.
Este problema no serš¢ fš¢cil de resolver porque la dificultad de los retos que los humanos pongan a estas mš¢quinas serš¢ cada vez mš¢s difšªcil: ¡°Esa discordancia en expectativas humanas de dificultad y los errores en los sistemas, empeorarš¢. La gente cada vez pondrš¢ metas mš¢s difšªciles para estos modelos y prestarš¢ menos atenciš®n a las tareas mš¢s sencillas. Eso seguirš¢ asšª si los sistemas no se dise?an de otra manera¡±, dice Zhou.
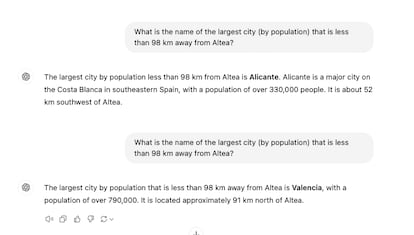
Estos programas evitan cada vez mš¢s disculparse por no saber algo. Esa seguridad irreal hace que los humanos se decepcionen mš¢s cuando la respuesta acaba siendo errš®nea. El artšªculo prueba que los humanos creen a menudo que son correctos resultados incorrectos que ofrecen en tareas difšªciles. Esta aparente confianza ciega, unido a que los nuevos modelos tienden a responder siempre, no da muchas esperanzas para el futuro, segš²n los autores.
¡°Los modelos de lenguaje especializados en š¢reas sensibles como la medicina podršªan dise?arse con opciones de rechazo¡± a responder, dice el artšªculo, o colaborar con supervisores humanos para que sepan mejor cuš¢ndo deben abstenerse de responder. ¡°Hasta que esto se logre, y dado el alto uso de estos modelos en la poblaciš®n general, llamamos a la concienciaciš®n sobre el riesgo que supone depender de la supervisiš®n humana para estos sistemas, especialmente en š¢reas donde la verdad es cršªtica¡±, escriben en el artšªculo.
En opiniš®n de Pablo Haya, investigador del Laboratorio de Lingš¹šªstica Informš¢tica de la Universidad Autš®noma de Madrid, en declaraciones a SMC Espa?a, el trabajo sirve para entender mejor el alcance de estos modelos: ¡°Desafšªa la suposiciš®n de que escalar y ajustar estos modelos siempre mejora su precisiš®n y alineaciš®n¡±. Y a?ade: ¡°Por un lado, observan que, aunque los modelos mš¢s grandes y ajustados tienden a ser mš¢s estables y a proporcionar respuestas mš¢s correctas, tambišŠn son mš¢s propensos a cometer errores graves que pasan desapercibidos, ya que evitan no responder. Por otro lado, identifican un fenš®meno que denominan ¡®discordancia de la dificultad¡¯ y que revela que, incluso en los modelos mš¢s avanzados, los errores pueden aparecer en cualquier tipo de tarea, sin importar su dificultad¡±.
Un remedio casero
Un remedio casero para resolver estos errores, segš²n el artšªculo, es adaptar el texto de la peticiš®n: ¡°Si le preguntas varias veces va a mejorar¡±, dice Zhou. Este mšŠtodo implica cargar al usuario con la responsabilidad de acertar con su pregunta o adivinar si la respuesta es correcta. Cambios sutiles en el prompt (peticiš®n) como ¡°?podršªas responder?¡±, en lugar de ¡°por favor, responde a lo siguiente¡±, darš¢ diferentes niveles de precisiš®n. Pero el mismo tipo de pregunta puede funcionar para tareas difšªciles y mal para sencillas. Es un juego de prueba y acierta.
El gran problema futuro de estos modelos es que su presunto objetivo es lograr una superinteligencia capaz de resolver problemas que los humanos son incapaces de asumir por falta de capacidad. Pero, segš²n los autores de este artšªculo, ese camino no tiene salida: ¡°El modelo actual no nos llevarš¢ a una IA superpoderosa que pueda solucionar la mayoršªa de tareas de una manera fiable¡±, afirma Zhou.
Ilya Sutskever, cofundador de OpenAI y uno de los cientšªficos mš¢s influyentes del sector, acaba de fundar una nueva compa?šªa. En declaraciones a Reuters admitiš® algo parecido: este camino estš¢ agotado. ¡°Hemos identificado una monta?a que es un poco diferente de lo que estaba trabajando, una vez subas a su cima, el modelo cambiarš¢ y todo lo que sabemos sobre la IA cambiarš¢ una vez mš¢s¡±, dijo. Zhou estš¢ de acuerdo: ¡°En cierto modo apoya nuestros argumentos. Sutskever ve que el modelo actual no basta y busca nuevas soluciones¡±.
Estos problemas no implican que estos modelos no sirvan para nada. Los textos o ideas que proponen sin que haya detrš¢s una verdad fundamental siguen siendo vš¢lidos. Aunque cada usuario deberš¢ asumir su riesgo: ¡°Yo no me fiaršªa por ejemplo del resumen de un libro de 300 pš¢ginas¡±, explica Zhou. ¡°Seguro que hay un montš®n de informaciš®n š²til, pero no me fiaršªa al 100%. Estos sistemas no son deterministas, sino aleatorios. En esa aleatoriedad pueden incluir algš²n contenido que se desvšªe del original. Es preocupante¡±, a?ade.
Este verano se hizo cšŠlebre entre la comunidad cientšªfica el caso de una investigadora espa?ola que mandš® al ComitšŠ Europeo de Protecciš®n de Datos una pš¢gina de referencias llena de nombres y enlaces alucinados en un documento precisamente sobre auditar la IA. Ha habido otros casos en tribunales y por supuesto multitud que han pasado sin ser detectados.
Tu suscripciš®n se estš¢ usando en otro dispositivo
?Quieres a?adir otro usuario a tu suscripciš®n?
Si continš²as leyendo en este dispositivo, no se podrš¢ leer en el otro.
FlechaTu suscripciš®n se estš¢ usando en otro dispositivo y solo puedes acceder a EL PA?S desde un dispositivo a la vez.
Si quieres compartir tu cuenta, cambia tu suscripciš®n a la modalidad Premium, asšª podrš¢s a?adir otro usuario. Cada uno accederš¢ con su propia cuenta de email, lo que os permitirš¢ personalizar vuestra experiencia en EL PA?S.
?Tienes una suscripciš®n de empresa? Accede aqušª para contratar mš¢s cuentas.
En el caso de no saber quišŠn estš¢ usando tu cuenta, te recomendamos cambiar tu contrase?a aqušª.
Si decides continuar compartiendo tu cuenta, este mensaje se mostrarš¢ en tu dispositivo y en el de la otra persona que estš¢ usando tu cuenta de forma indefinida, afectando a tu experiencia de lectura. Puedes consultar aqušª los tšŠrminos y condiciones de la suscripciš®n digital.
Sobre la firma

Mš¢s informaciš®n

































































